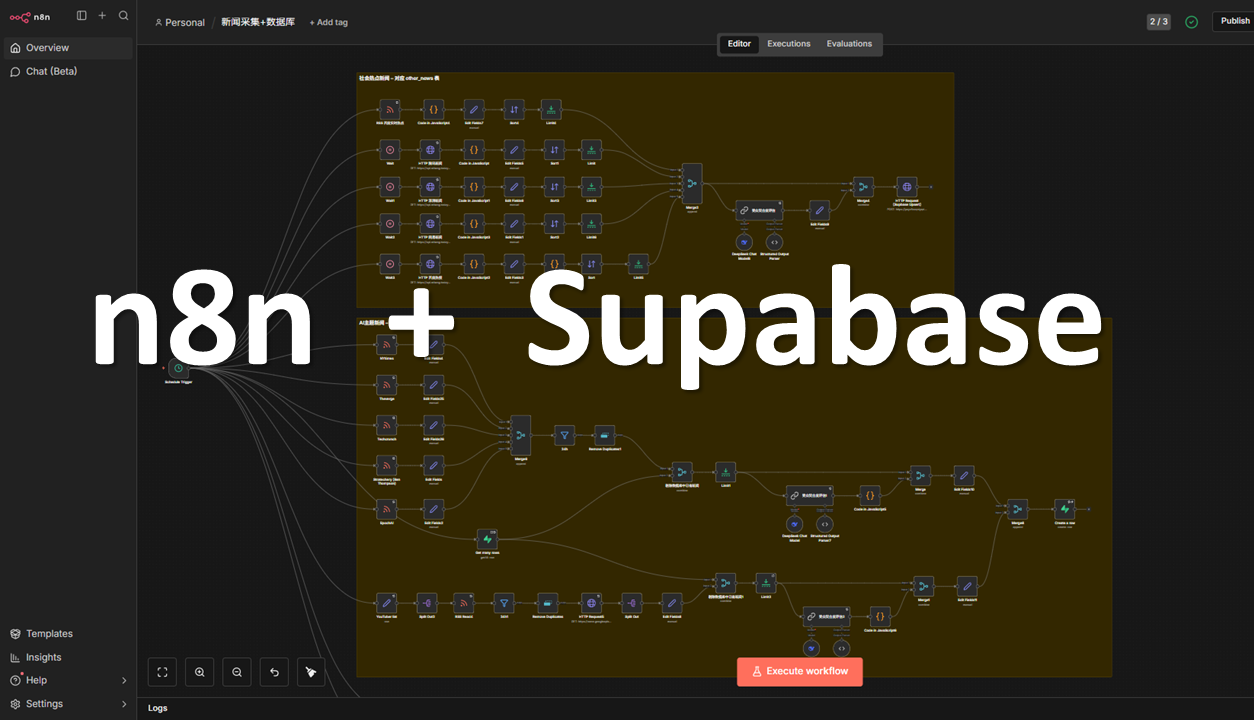
在 AI 行业信息爆炸的背景下,传统的人工搜集与选题方式已无法满足高效内容创作的需求。本项目构建了一套 “全链路自动化情报引擎”,通过 n8n 编排工作流,实现从全球多源信息采集、AI 深度语义加工、到结构化数据入库及爆款选题评估的全自动化。该系统不仅是信息的搬运工,更是基于 JTBD (Jobs-to-be-Done) 理论的决策支持系统,旨在将碎片化资讯转化为可执行的自媒体资产。
1. 系统架构
系统采用“管道式”架构,分为数据采集、智能加工、数据存储三个核心层级:
- 数据采集层:通过 RSS 订阅、HTTP Request 接入 API 等方式,实现全网社会新闻(百度热搜、澎湃新闻、腾讯新闻、网易新闻等)和AI新闻(NYTimes、The Verge、TechCrunch、YouTube频道等)的监控和采集。并事先定义 “营销日历” 形式整理的社会热点。
- 智能加工层:通过结构化 Prompt 工程,引导 LLM 完成翻译、摘要、主题打标、情绪动机剖析及爆款潜力评估。
- 数据存储层:以 Supabase (PostgreSQL) 作为单一事实来源(SSOT)。
2. 核心模块详解
2.1 智能语义与情报提炼
- 受众匹配度评估:基于核心受众画像,引入热点事件与核心受众生活的”关联度“与“兴趣度”评分,实现热点事件的优先级排序。
- 情绪与痛点映射:将新闻映射至核心受众的“焦虑、懒惰、贪婪、共鸣”等底层动机,为选题提供情绪价值支撑。
- JTBD 深度解构:不同于传统的摘要提取,系统强制 LLM 使用 JTBD 标准句式(“当 [特定情境] 时,我想要 [做什么],以便于 [最终目标]”),强迫 AI 站在受众视角思考。
- 创新与批判性视角:结合“投资人毒舌点评”与“反共识视角解构”,为博主提供批判性的选题建议,避免平庸的选题进入创作池。
2.2 自动化工作流编排 (n8n)
- 数据标准化:通过 Code 节点对不同来源(RSS/API)的数据进行清洗,剥离 HTML 标签、修复 XML 字符错误(如 & 符号转义),确保数据格式统一。
- 去重机制:利用 Remove Duplicates 节点和 Supabase 的 on_conflict 策略,确保同一新闻不会被重复写入数据库。
- 人工介入 (Human-in-the-Loop):通过 Webhook,实现了 “AI 生成 -> 人工审核 -> 反馈并优化” 的闭环持续迭代,提示选题质量。
3. 工作流展示
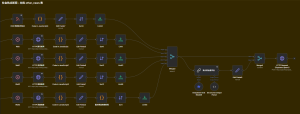
- 社会新闻采集入库:社会新闻信息采集清洗并存储到数据库中。
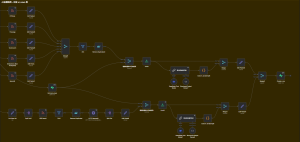
- AI新闻采集入库:AI 新闻信息采集清洗并存储到数据库中。
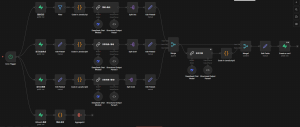
- 选题分析:挖掘新闻及社会热点事件对受众心理的影响,分析受众深层需求及选题探讨方向。
4. 选题输出示例
根据自媒体账号主题和核心受众定位输出选题分析结果(示例偏重AI技术+身心灵视角):
|
选题来源 |
事件 | 受众底层需求 | 受众情绪痛点 | 选题潜力评估 |
选题建议 |
| 社会新闻 | 董明珠说了句大实话:关键在于切实解决就业问题、持续提升居民工资待遇。 | 当面临职场内卷和收入增长停滞时,我想要找到一个能稳定提升收入或发展副业的低风险路径,以便于缓解对未来的财务焦虑,获得职业安全感。 | 工作很努力但工资不涨,担心被裁员,对未来收入没有信心,想搞副业又怕失败或没时间。 | 直击白领对“就业难”和“工资低”的核心生存焦虑,极易引发“说的就是我”的强烈共鸣,对解决方案有迫切需求。 | 共识是向外求索(找副业、跳槽、卷技能),反共识是向内整合。真正的‘稳定提升’不在于增加一个收入来源,而在于将现有主业‘AI化’,用AI将你的核心工作产出效率提升300%,从而在内部谈判中获取溢价或创造‘时间盈余’。焦虑源于对自身‘可被替代部分’的无力感,降熵的关键是识别并让AI接管这些部分,将人的精力聚焦于决策、创造和关系——这些AI无法替代的修行道场。 |
| 社会新闻 | 委员建议:劳动者退休后养老待遇应平等!引发对养老金差距的广泛讨论。 | 当担忧未来养老金不足,无法维持理想退休生活时,我想要现在就能开始一套简单、可持续的个人养老规划方案,以便于对冲未来的不确定性,获得老年生活的安全感与希望。 | 对复杂的社保政策感到困惑,担心自己退休后收入骤降、生活品质下降,但不知道从现在开始该如何具体规划和储蓄,充满对遥远未来的无力感。 | 将宏大的社会议题转化为与每个职场人息息相关的“个人养老规划”问题,直击最深层的生存焦虑,提供解决方案能带来强烈的希望感和实用价值。 | 主流叙事是‘多存钱、早投资’制造更多焦虑。反共识视角是:养老焦虑的本质是对‘线性时间’和‘确定性未来’的执念。修行人视角的降维解构:1. 认知套利:将养老规划从‘储蓄竞赛’重构为‘能力与收入流建设’。核心不是存下工资的X%,而是用AI杠杆,在退休前打造出至少1个自动化或半自动化的‘数字资产’(如AI辅助的知识产品、可持续内容),其生命周期远超你的职业生涯。2. 情绪降熵:接受未来本就不可控。真正的安全感源于‘当下创造价值的能力’及‘对变化的适应力’。规划的重点应是利用AI持续提升这两项‘元能力’,而非死磕一个数字目标。从‘为未来存钱’转向‘用未来思维建设现在’。 |
| AI新闻 | 开源开发者个人项目在六周内走红并获Docker官方合作,成为个人通过开源创新实现快速突破的励志范例。 | 当 [我想通过做一个副业项目来证明自己、增加收入或打造个人品牌,但不知从何入手且担心投入没有回报] 时,我想要 [看到一个低技术门槛、可快速验证的副业成功路径和具体故事],以便于 [获得启动的信心和方向,相信自己也有机会通过小而美的创新获得认可]。 | 贪婪(渴望低风险高回报的副业机会)与焦虑(担心自己想法不值钱、技术不够、或努力白费)。 | “六周逆袭”的极速成功故事极具冲击力和模仿诱惑,完美契合了受众对“轻量副业搞钱”和“个人价值被大厂认可”的双重渴望,提供了希望感和具体参照。 | 真正的‘逆袭’不是复制一个无法复制的故事,而是解构‘成功’本身。反共识视角:大众渴望的是‘结果被认可’,而修行者应追求‘过程即奖励’。将‘六周获Docker合作’降维解构为‘六周构建一个可对话的资产’。认知套利:成功的关键不是‘被大厂看见’,而是‘先让自己被自己看见’——通过AI工具,将任何微小的专业知识(如Excel技巧、PPT排版)封装成一个可交互、可传播的‘微产品’。情绪降熵:从‘我必须做一个轰动项目’的妄念,转向‘我每天用AI固化一点我的智慧’的踏实,内耗自消。 |
| 营销日历 | 世界睡眠日 | 当世界睡眠日来临,我想围绕‘熬夜’‘失眠’话题创作内容(如图文、短视频),以便于吸引同样被睡眠问题困扰的粉丝,建立‘懂你’的亲切感,并为后续推荐相关产品或生活方式做铺垫。 | 知道睡眠重要但改不掉熬夜刷手机的习惯,想分享自己的挣扎却怕内容流于俗套(如单纯晒黑眼圈),缺乏一个能引发深度共鸣、又不至于显得自己很‘丧’的独特切入角度和表达方式。 | 睡眠问题是都市职场人的普遍痛点,内容极易引发‘你懂我’的强烈共鸣,是快速建立情感连接、积累精准粉丝的高效话题。 | 别再把‘熬夜’当成需要克服的‘坏习惯’。从修行视角看,它是现代人‘神’(注意力)被数字世界(AI/信息流)过度消耗后的‘失守’,是‘识神’(后天思维)压制‘元神’(先天本能)的失衡。从AI视角看,熬夜是个人生物钟与算法推荐系统‘上瘾模型’的对抗失败。破局点在于:承认熬夜是‘系统性问题’,而非‘个人意志力问题’。解决方案不是‘对抗熬夜’,而是‘用AI重新设计你的夜间环境场’,用修行心法‘观照’而非‘批判’熬夜时的自己,完成从‘自责内耗’到‘观察调整’的认知套利,实现情绪降熵。 |
5. 未来改进方向
- 支持多账号自动配置:将系统架构从 “硬编码” 调整转向 “模块化配置”,以支持题系统自适应不同主题的账号。只需在数据库中预先存入与账号相关的信息,如 “主题定位” 和 “受众画像”,系统即可自动配置生成与之匹配的 Prompt ,从而让工作流产生适配该账号的选题。
- 工作流闭环优化:引入人工对选题建议的评估反馈,引导系统根据人工反馈调整提示词并优化选题。